
روش هایی برای بهینه کردن مدل تبولار
هر مدل تبولار در هسته خود یک پایگاه داده ستونی در حافظه به نام Vertipaq دارد.این موتور بهینه سازی شده مدل را در RAM ذخیره می کند و اطلاعات را در ستون هایی با ساختار خاص خود که از نظر فیزیکی از یکدیگر جدا شده اند، تبدیل، و فشرده می کند.
پایگاه داده های ستونی به ما این امکان را می دهند که اقدامات سریع را روی یک ستون انجام دهیم. با این حال، محاسبات شامل بسیاری از ستون ها به زمان (و چرخه های CPU) بیشتری برای محاسبه اندازه گیری نهایی نیاز دارد.راه های مختلفی وجود دارد که از طریق آنها می توان مدل های تبولار را بهینه کرد. این بهینه کردن اساساً بر اساس ویژگی های مدل و هدف اصلی شما متفاوت هستند.این مقاله چند نکته کاربردی را ارائه میکند که میتواند برای افزایش عملکرد موتور هر مدل تبولار به کار رود.
۱-بهینه کردن مدل
از نظر تئوری، بهترین راه برای بهبود مدل تبولار، گردآوری تمام اطلاعات در یک جدول واحد است. اگرچه، این رویکرد منجر به یک فرآیند ETL بسیار کند و گران می شود که توصیه نمی شود
بنابراین، بهترین کار این است که مدل تبولار خود را بسازید، به خصوص مدل های پیچیده با روابط زیاد بین جداول بزرگ، با استفاده از روش “مدل سازی کیمبال” یا همان مدل Star Schemas. این رویکرد جداول ” fact” و ” dimensions” را بهینه می کند و تفسیر داده ها را ساده می کند.
۲) حذف ستون های استفاده نشده
Vertipaq Analyzer یک ابزار بسیار مفید و کم هزینه است که می تواند با تجزیه و تحلیل جداول و اندازه ستون ها، به پیدا کردن گران ترین ستون ها یا جداول به ما کمک کند.در پست های بعدی برای درک بهتر در مورد ابزار Vertipaq Analyzer توضیح داده خواهد شد.
این موارد، زمانی که برای تجزیه و تحلیل داده ها لازم نباشد، همیشه باید حذف شوند. ستونهایی با کاردینالیته بالا (یعنی با تعداد مقادیر متمایز زیاد) مانند Timestamp یا کلید اصلی در جدول Fact بسیار گران هستند و با حذف آنها حافظه زیادی آزاد میکنید و در نتیجه عملکرد مدل داده خود را بسیار بهبود میبخشید
هر ستون موجود در یک مدل SSAS Tabular توسط موتور Vertipaq با استفاده از یکی از این تکنیکهای زیر فشرده و ذخیره میشود:
کدگذاری مقدار: Value Encoding
رمزگذاری هشDictionary (Hash) Encoding:
کدگذاری مقدار: Value Encoding:
Value Encoding:
یک الگوریتم است که فقط می تواند برای ستون های عددی اعمال شود. با استفاده از این تکنیک ریاضی، Vertipaq سعی می کند تعداد بیت های مورد نیاز برای ذخیره داده ها را بر اساس محدوده مقادیر موجود در ستون کاهش دهد. در زیر مثالی برای درک بهتر این الگوریتم اورده شده است.
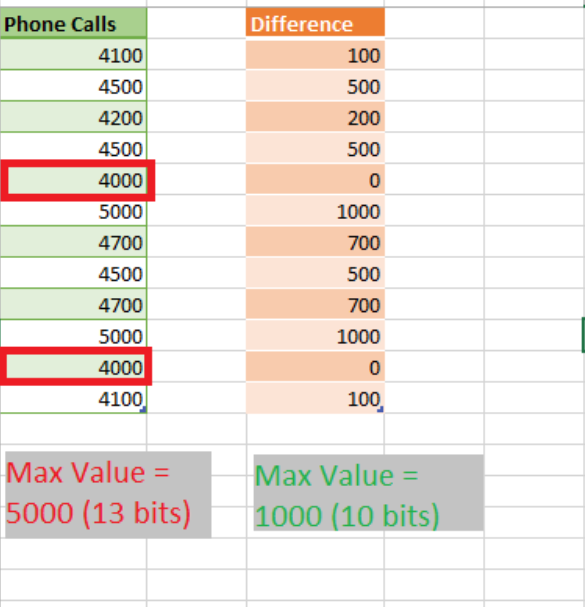
همینطور که در شکل دیده میشود مقادیر به بیت های کوجکتر ذخیره میشود.
رمز گذاری هش Hash encoding
این نوع احتمالا پر استفاده ترین نوع فشرده سازی توسط VertiPaq است. با استفاده از رمزگذاری هش، VertiPaq یک فرهنگ لغت از مقادیر متمایز در یک ستون ایجاد می کند و پس از آن مقادیر “واقعی” را با مقادیر شاخص از فرهنگ لغت جایگزین می کند. در زیر مثالی برای آن اورده شده است.
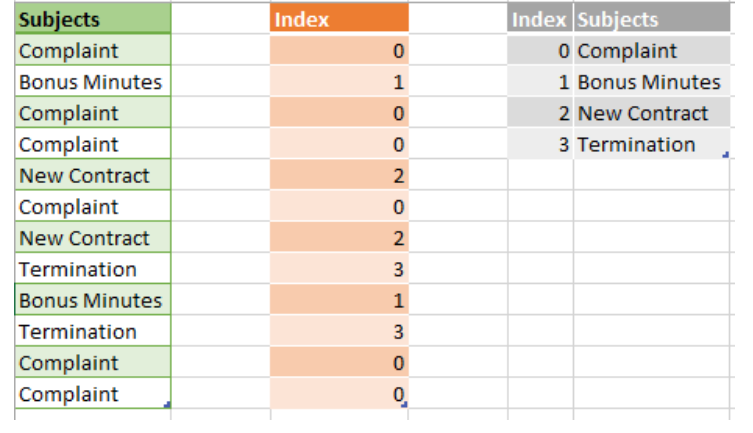
۳)کاهش تعداد مقادیر اما نه اطلاعات
گاهی اوقات، هنگام داشتن ستونهایی با مقادیر مختلف، توصیه میشود که محتوای آنها را به ستونهایی تقسیم کنید (هر کدام با تعداد کمتری مقادیر متمایز) که میتوان آنها را برای به دست آوردن ستون اصلی ترکیب کرد. با انجام این کار، اندازه را کاهش می دهیم و متعاقباً فشرده سازی داده ها را بهینه می کنیم. به عنوان مثال، اگر یک ستون زمان تاریخ حاوی Timestamp دارید، تقسیم داده ها به دو ستون بسیار کارآمدتر است: یکی برای تاریخ و دیگری برای زمان.
۴) کاهش دقت
مواردی وجود دارد که دقت یک ستون خاص در مدل داده شما نیازی نیست. در این موارد، گرد کردن مقادیر ستون (اعم از زمان های تاریخ یا عددی ) باعث کاهش کاردینالیته آن و در نتیجه صرفه جویی در فضای زیادی در حافظه می شود.حذف کلی تعداد مقدار اعشار یا کم کردن مقدار اعشار از ۵ رقم به ۲ رقم.
۵) انتخاب مژر به جای ستون های محاسبه شده
ستون های محاسبه شده می توانند بسیار هزینه بر باشند. در برخی موارد، می توان با ایجاد یک مژر ساده به جای محاسبه یک ستون استفاده کرد.به عنوان مثال، در جدول زیر، ستون محاسبه شده «مبلغ فروش» از ضرب «مقدار» در «قیمت واحد» به دست آمده است.یک راه ممکن برای بهینه سازی این اطلاعات این است که فقط «تعداد» و «قیمت واحد» را ذخیره کنید و به سادگی از فرمول DAX زیر برای به دست آوردن «مقدار فروش» استفاده کنید:

Sales[Sales Amount] = SUMX(Sales, Sales[Quantity]* Sales[Unit Price])
۶)مقادیر دایمنشن استفاده نشده را فیلتر کنید
اگر رکوردهایی در دایمنشن مدل خود دارید که در جداول Fact ارجاع داده نمی شوند، برای صرفه جویی در فضا، بهترین کار فیلتر کردن آنهاست. به عنوان مثال، اگر در دایمنشن تاریخ خود ۳.۰۰۰.۰۰۰ رکورد دارید در حالی که فقط ۹۲ مورد از آنها در جدول fact استفاده می شود، باید جدول دایمنشن را فیلتر کنید تا فقط این مقادیر حفظ شود. در مدل های بزرگتر و پیچیده تر، این تکنیک از نظر صرفه جویی در حافظه و عملکرد مدل واقعاً مهم است
۷) از انواع داده های ارزان تر استفاده کنید
برخی از انواع داده، برای SSAS Tabular، گرانتر از سایرین ذخیره میشوند. به عنوان مثال، استفاده از Date over Date Time یا Integer ID به جای String می تواند عملکرد مدل داده شما را بهبود بخشد. اندازه هر نوع داده تنها بر اساس محدوده مقادیری که نشان می دهند متفاوت است.
۸) DAX خود را بهینه کنید
۱- به جای تکرار مژرها در داخل if از متغیرها استفاده کنید (تعداد دفعاتی که یک expression داده شده محاسبه می شود را کاهش می دهد).
۲- به جای “/” از تابع DIVIDE() استفاده کنید. تابع Divide پارامتر سومی دارد که میتوان آن را مشخص کرد و هر زمان که مخرج ۰ باشد، برگرداند. اگر مطمئن هستید که مخرج شما هرگز ۰ نخواهد بود، بهتر است از عملگر “/” استفاده کنید.
۳- مقادیر BLANK را با صفر یا رشته های دیگر جایگزین نکنید، اگر الزامی نیست. بهطور پیشفرض، تمام ردیفهای دارای مقادیر BLANK بهطور خودکار در گزارش فیلتر میشوند. جایگزینی آن مقادیر بر عملکرد تأثیر منفی می گذارد.
۴- از SELECTEDVALUE() به جای HASONEVALUE() استفاده کنید. بسیاری از اوقات، تابع HASONEVALUE() برای بررسی اینکه آیا فقط یک مقدار متمایز در یک ستون مشخص وجود دارد یا خیر استفاده می شود. پس از آن معمولاً تابع VALUES() برای بازیابی آن اعمال می شود. SELECTEDVALUE() به خودی خود هر دو مرحله را انجام می دهد.
۵- اگر می خواهید تعدادی از ستون ها را گروه بندی کنید و تجمع حاصل را برگردانید، همیشه به جای SUMMARIZE() از SUMMARIZECOLUMNS () استفاده کنید. SUMMARIZECOLUMNS () جدیدتر و بهینه تر است.
دیدگاه خود را ثبت کنید
تمایل دارید در گفتگوها شرکت کنید؟در گفتگو ها شرکت کنید.